In the research of PCIE 3.0 versus PCIE 4.0, I became serious about the actual application scenario. What’s the real bandwidth between CPU and GPU when we are training a deep learning model?
Finally, I got this tool: pcm
After building it, I run “sudo ./bin/pcm” and got this:
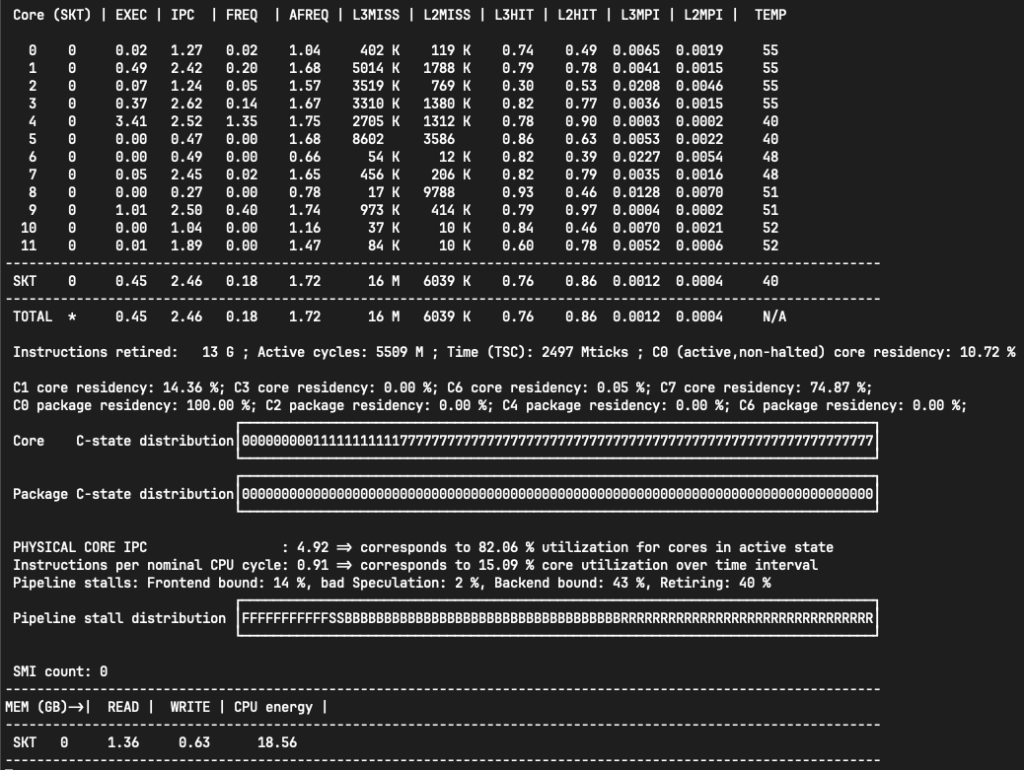
Grateful that I can even see the IPC(Instructions Per Cycle), and L2/L3 hit ratio from this tool. But my most interesting metric is the PCIE bandwidth. Where is the PCIE bandwidth?
I tried “sudo bin/pcm-pcie” but it said my desktop CPU (i5-12400) is not supported:
The processor is not susceptible to Rogue Data Cache Load: yes The processor supports enhanced IBRS : yes Package thermal spec power: 65 Watt; Package minimum power: 0 Watt; Package maximum power: 0 Watt; INFO: Linux perf interface to program uncore PMUs is present For non-CSV mode delay < 1.0s does not make a lot of practical sense. Default delay 1s is used. Consider to use CSV mode for lower delay values Update every 1 seconds Detected 12th Gen Intel(R) Core(TM) i5-12400 "Intel(r) microarchitecture codename Alder Lake" stepping 5 microcode level 0x2c Jaketown, Ivytown, Haswell, Broadwell-DE, Skylake, Icelake, Snowridge and Sapphirerapids Server CPU is required for this tool! Program aborted Cleaning up Closed perf event handles Zeroed uncore PMU registers
Then a new idea jumped out of my mind: what my CPU do in my application is only read data from file and push them to GPU, so the bandwidth of reading memory is approximately the writing bandwidth of PCIE!
To verify my idea, I changed my model from “tf_efficientnetv2_s_in21k” to “tf_mobilenetv3_small_075” (using a smaller model could let CPU pump more data into GPU)
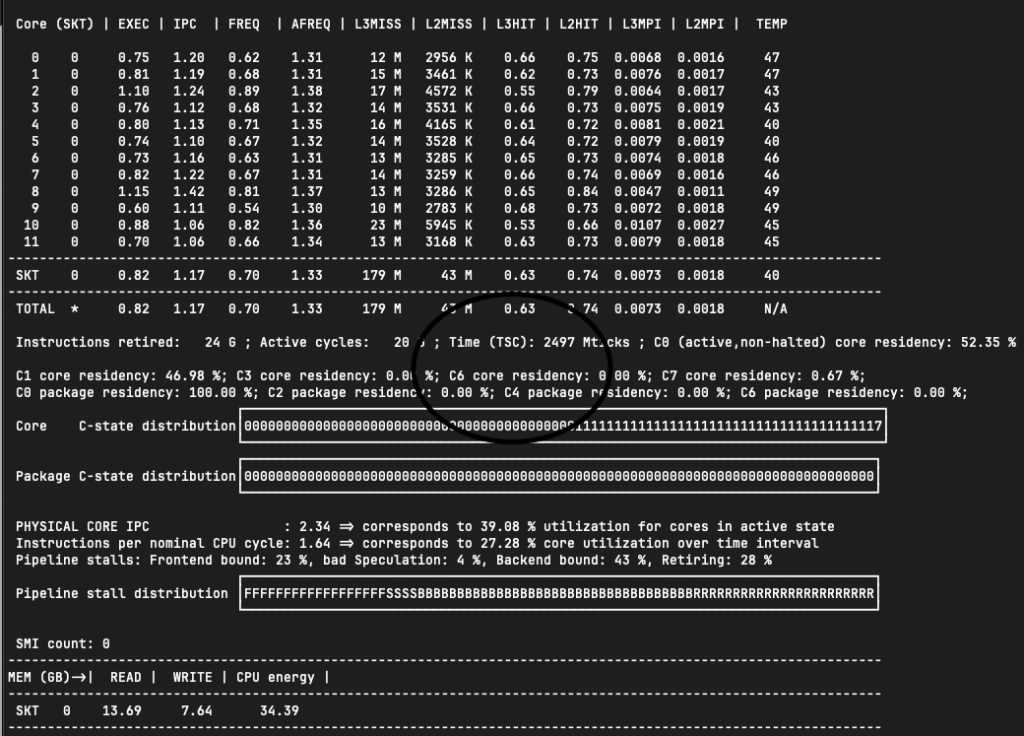
As we can see, the bandwidth of READ memory increased from “1.36GB” to “13.69GB”. This shall be equal to the bandwidth of PCIe (since the data from memory will only go to the GPU).
Seems we really need PCIE 4.0 for deep learning 🙂




 Loggerhead Shrike
Loggerhead Shrike Anhinga
Anhinga Eastern Meadowlark
Eastern Meadowlark