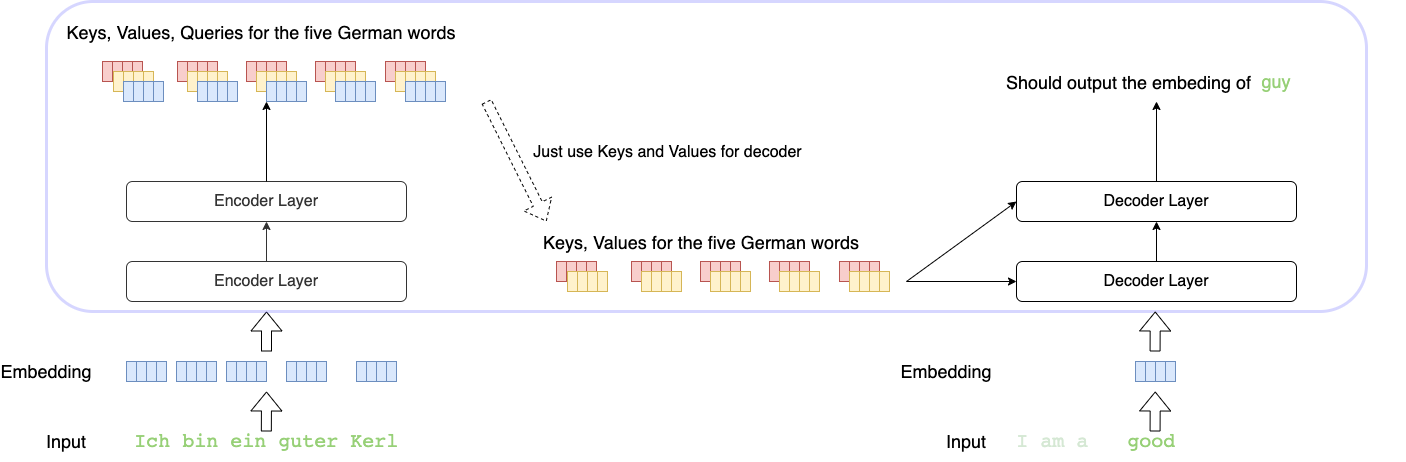
For NLU (Natural Language Understanding), we use the bidirectional language model (like BERT), but for NLG(Natural Language Generation), the left-to-right unidirectional language model (like GPT) is the only choice.

Could we accomplish these two tasks by using one unified language model?
In this paper, the authors use a mask matrix to run different tasks in the same model:

The pivotal equation for this method is:
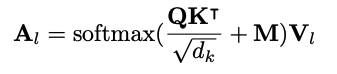
“M is the mask matrix and determines whether a pair of tokens can be attended to each other.”
“Unidirectional LM is done by using a triangular matrix for the self-attention mask M (as in the above equation), where the upper triangular part of the self-attention mask is set to −∞, and the other elements to 0”
“Within one training batch, 1/3 of the time we use the bidirectional LM objective, 1/3 of the time we employ the sequence-to-sequence LM objective, and both left-to-right and right-to-left LM objectives are sampled with the rate of 1/6”
Keep a note that the training process use bidirectional/unidirectional/seq2seq objective, not samples)